Shockingly, Most Reddit Environmentalists are not Greta Thunberg
R
Data Mining
API
NLP
Large Language Models
Document Embeddings
Sentiment Analysis
Social Media
Multilevel Modeling
Author
Louis Teitelbaum
Published
July 12, 2023
Greta Thunberg may be the most well-known climate activist today. Along with her climate activism, she is known for her psychiatric diagnoses. In fact, these two aspects of her public persona often go together - autism and anxiety disorders are the superpowers that allow her to take a principled stand.
I was diagnosed with Asperger’s syndrome, OCD, and selective mutism… I think that in many ways, we autistic are the normal ones, and the rest of the people are pretty strange, especially when it comes to the sustainability crisis, where everyone keeps saying that climate change is an existential threat and the most important issue of all and yet they just carry on like before. 1
Told by Thunberg herself, this is an inspiring and compelling claim. But is it true in general that autistic and/or anxious thought patterns cause people to take the sustainability crisis more seriously? Is this true even when it comes to smaller-scale activism than Thunberg’s - say, involvement with environmentalist groups on Reddit?
Gathering Data
Using the RedditExtractoR package in R, I gathered data on all threads over the last month from seven environmentalist communities on Reddit: r/Environmentalism, r/sustainability, r/ZeroWaste, r/climate, r/environment, r/SustainabilityPorn, and r/Green.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.6
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.1 ✔ tibble 3.3.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.2
✔ purrr 1.2.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(quanteda)
Package version: 4.3.1
Unicode version: 14.0
ICU version: 71.1
Parallel computing: 12 of 12 threads used.
See https://quanteda.io for tutorials and examples.
library(quanteda.sentiment)
Attaching package: 'quanteda.sentiment'
The following object is masked from 'package:quanteda':
data_dictionary_LSD2015
As a control group, I chose seven communities with broadly similar themes, but without any sustainability-specific agenda: r/worldnews, r/makerspace, r/NoStupidQuestions, r/gardening, r/politics, r/relationship_advice, and r/news.
In my last post, I explored various methods of quantifying psychological content in text, including contextualized construct representation (CCR)2, which leverages the power of large language models to turn established psychiatric questionnaires into embeddings - lists of activations of neurons in the model - that can be compared to the same model’s embeddings of other texts.
Toward the end of that post, I raised a potential difficulty with this method: How can I be sure that I am not measuring the extent to which people write like they’re writing a questionnaire? This is critical, since questionnaires tend to be written in formal, well organized, full sentences, and certain psychological constructs might lead to people writing less - or more - like that.
The solution I proposed was to create a “neutralized” version of the questionnaire average embedding, which reflects each original question and its grammatical negation. By subtracting out this neutralized embedding (which nevertheless maintains its questionnaire-ness all around) from the original embedding, I can isolate the psychological construct of interest without fear of confounds from the particular writing style of the questionnaire. This is the approach I will take here, using the Adult Social Behavior Questionnaire (ASBQ)3 for clinical assessment of autism spectrum disorder in adults. The questionnaire includes six subscales: reduced contact, reduced empathy, reduced interpersonal insight, violations of social conventions, insistence on sameness, and sensory stimulation and motor stereotypes. Excluding the last one (I have a hard time imagining how it would apply to Reddit activity), I will treat each subscale on its own.
As in my last post, I am using embeddings from the second to last layer of BERT (base uncased).
# Adult Social Behavior Questionnaire (ASBQ); self-report, excluding 'sensory stimulation and motor stereotypes'reduced_contact <-c("i do not take the initiative in contacts with other people","i have little or no interest in socializing with others","i ignore invitations from others to do something with them","i avoid people who try to make contact with me","the only contact i have with others is when i have to buy something or arrange something, for example with people in a shop or in a government office","i am a loner, even in a group i hold myself apart","i do not enjoy doing things with other people, for example, doing a chore together or going somewhere together" )reduced_empathy <-c("i find it difficult to put myself in someone else’s shoes, for example, i can not see why someone is angry","i am unaware of other people’s emotional needs, for example, i do not encourage other people or reassure them","i find it hard to sense what someone else will like or think is nice","i am not really bothered by someone else in pain","i do not notice when someone is upset or has problems","the reason why i would contact others is to get things done rather than because i am interested in them","i do not show sympathy when others hurt themselves or are unhappy" )reduced_interpersonal_insight <-c("i do not get jokes","i take everything literally, for example, i do not understand certain expressions","i am very naïve; i believe everything i am told","it is easy to take advantage of me or get me to do other people’s dirty work","i do not notice when others make fun of me","i find it hard to follow the gist of a conversation—i miss the point","i need an explanation before i understand the meaning behind someone’s words","i give answers that are not relevant because i have not really understood the question" )violations_of_social_conventions <-c("i do not differentiate between friends and strangers, for example, i do not care who i am with","i seek contact with anyone and everyone; i show no reserve","i touch people when it is not suitable, for example, i hug virtual strangers","the questions i ask are too personal, or i tell others things that are too personal","i behave the same wherever i am; it makes no difference to me whether i am at home or somewhere else (visiting others, at work, in the streets)","i ask strangers for things i need, for example for food or drink if i am hungry or thirsty" )insistence_on_sameness <-c("i panic when things turn out differently than i am used to","i resist change; if it were left up to me, everything would stay the same","i want to do certain things in exactly the same way every time","i do not like surprises, for example, unexpected visitors","i do not like a lot of things happening at once","i really need fixed routines and things to be predictable","i hate it when plans are changed at the last moment","it takes me ages to get used to somewhere new" )#~~~~~~~~~~~~~~~~~~~~~~~~# Negated Versionsreduced_contact_neg <-c("i take the initiative in contacts with other people","i have lots of interest in socializing with others","i do not ignore invitations from others to do something with them","i do not avoid people who try to make contact with me","i have contact with others all the time, not just when i have to buy something or arrange something, or with people in a shop or in a government office","i am not a loner, in a group i do not hold myself apart","i enjoy doing things with other people, for example, doing a chore together or going somewhere together" )reduced_empathy_neg <-c("i do not find it difficult to put myself in someone else’s shoes, for example, i can see why someone is angry","i am aware of other people’s emotional needs, for example, i encourage other people or reassure them","i do not find it hard to sense what someone else will like or think is nice","i really bothered by someone else in pain","i notice when someone is upset or has problems","the reason why i would contact others is because i am interested in them rather than to get things done","i show sympathy when others hurt themselves or are unhappy" )reduced_interpersonal_insight_neg <-c("i get jokes","i do not take everything literally, for example, i understand expressions","i am not very naïve; i do not believe everything i am told","it is not easy to take advantage of me or get me to do other people’s dirty work","i notice when others make fun of me","i do not find it hard to follow the gist of a conversation—i do not miss the point","i do not need an explanation before i understand the meaning behind someone’s words","i give answers that are relevant because i have really understood the question" )violations_of_social_conventions_neg <-c("i differentiate between friends and strangers, for example, i care who i am with","i do not seek contact with anyone and everyone; i show reserve","i do not touch people when it is not suitable, for example, i do not hug virtual strangers","the questions i ask are not too personal; i do not tell others things that are too personal","i do not behave the same wherever i am; it makes a difference to me whether i am at home or somewhere else (visiting others, at work, in the streets)","i do not ask strangers for things i need, for example for food or drink if i am hungry or thirsty" )insistence_on_sameness_neg <-c("i do not panic when things turn out differently than i am used to","i do not resist change; if it were left up to me, nothing would stay the same","i do not want to do things in exactly the same way every time","i like surprises, for example, unexpected visitors","i like a lot of things happening at once","i do not really need fixed routines or things to be predictable","i do not hate it when plans are changed at the last moment","it does not take me ages to get used to somewhere new" )#~~~~~~~~~~~~~~~~~~~~~~~~# Generate Embeddings# Mean embeddings of each subscale and its negationreduced_contact <-textEmbed(reduced_contact)$texts[[1]] %>%summarise(across(Dim1_texts:Dim768_texts, mean)) %>%unlist(use.names=FALSE)reduced_empathy <-textEmbed(reduced_empathy)$texts[[1]] %>%summarise(across(Dim1_texts:Dim768_texts, mean)) %>%unlist(use.names=FALSE)reduced_interpersonal_insight <-textEmbed(reduced_interpersonal_insight)$texts[[1]] %>%summarise(across(Dim1_texts:Dim768_texts, mean)) %>%unlist(use.names=FALSE)violations_of_social_conventions <-textEmbed(violations_of_social_conventions)$texts[[1]] %>%summarise(across(Dim1_texts:Dim768_texts, mean)) %>%unlist(use.names=FALSE)insistence_on_sameness <-textEmbed(insistence_on_sameness)$texts[[1]] %>%summarise(across(Dim1_texts:Dim768_texts, mean)) %>%unlist(use.names=FALSE)reduced_contact_neg <-textEmbed(reduced_contact_neg)$texts[[1]] %>%summarise(across(Dim1_texts:Dim768_texts, mean)) %>%unlist(use.names=FALSE)reduced_empathy_neg <-textEmbed(reduced_empathy_neg)$texts[[1]] %>%summarise(across(Dim1_texts:Dim768_texts, mean)) %>%unlist(use.names=FALSE)reduced_interpersonal_insight_neg <-textEmbed(reduced_interpersonal_insight_neg)$texts[[1]] %>%summarise(across(Dim1_texts:Dim768_texts, mean)) %>%unlist(use.names=FALSE)violations_of_social_conventions_neg <-textEmbed(violations_of_social_conventions_neg)$texts[[1]] %>%summarise(across(Dim1_texts:Dim768_texts, mean)) %>%unlist(use.names=FALSE)insistence_on_sameness_neg <-textEmbed(insistence_on_sameness_neg)$texts[[1]] %>%summarise(across(Dim1_texts:Dim768_texts, mean)) %>%unlist(use.names=FALSE)# Neutralized Questionnaire - Initial - mean(Initial, Negated)reduced_contact_neutralized <- reduced_contact - (reduced_contact + reduced_contact_neg)/2reduced_empathy_neutralized <- reduced_empathy - (reduced_empathy + reduced_empathy_neg)/2reduced_interpersonal_insight_neutralized <- reduced_interpersonal_insight - (reduced_interpersonal_insight + reduced_interpersonal_insight_neg)/2violations_of_social_conventions_neutralized <- violations_of_social_conventions - (violations_of_social_conventions + violations_of_social_conventions_neg)/2insistence_on_sameness_neutralized <- insistence_on_sameness - (insistence_on_sameness + insistence_on_sameness_neg)/2
r/aspergers
My second metric for autistic tendencies is less sensitive to the nuances of various ASD symptoms, but is more directly tailored to the task at hand. The r/aspergers subreddit describes itself as “the internet’s largest community of people affected by Autism Spectrum Disorder”. So here, I am simply going to compute the average embedding of posts in this group and use it as a paradigm of the construct of interest.
I could easily take the same approach for anxiety as I did for autism. I could even use questionnaires designed specifically for OCD and selective mutism, the diagnoses mentioned by Greta Thunberg in the quote above. Nevertheless, I am going to use a different, more straightforward method: the Students Anxiety and Depression Dataset includes 733 handcoded examples of social media posts and comments that reflect anxiety. I will simply take the average BERT embedding of these as the quintessence of anxiety on social media.
As with ASD above, my second metric will simply be an average embedding of posts on a disorder-specific subreddit. This time, r/OCD.
OCD_threads <-find_thread_urls(subreddit ="OCD")OCD_threads$full_text <-preprocess(paste(OCD_threads$title, OCD_threads$text))OCD_threads_subset <-slice_sample(OCD_threads, n =100)# EmbeddingOCD_threads_embeddings <-textEmbed(OCD_threads$full_text)$texts[[1]]# Average EmbeddingOCD <- OCD_threads_embeddings %>%summarise(across(Dim1_texts:Dim768_texts, mean)) %>%unlist(use.names=FALSE)
Do environmentalists exhibit more autism and anxiety characteristics than control?
Now that I have vector representations of five autism subscales, generalized ASD, OCD, and anxiety, I can simply embed each comment in the Reddit data using the same method, and score them based on their cosine similarity to each construct embedding. Then I can use classical statistical methods to test whether environmentalists exhibit more autism and anxiety characteristics than control.
The aforementioned classical statistical methods do require some thought, though. Because the data were gathered from multiple communities, the samples are not independent, and fixed-parameter-only methods like t-tests will be biased. This is a job for multilevel modeling, with the intercept for each community allowed to vary freely around its group (environmentalist/non-environmentalist) mean.
library(lmerTest)
Loading required package: lme4
Loading required package: Matrix
Attaching package: 'Matrix'
The following objects are masked from 'package:tidyr':
expand, pack, unpack
Attaching package: 'lmerTest'
The following object is masked from 'package:lme4':
lmer
The following object is masked from 'package:stats':
step
reduced_contact_mod1 <-lmer(reduced_contact ~ environmentalist + (1| subreddit), data = comments_unified)reduced_empathy_mod1 <-lmer(reduced_empathy ~ environmentalist + (1| subreddit), data = comments_unified)reduced_interpersonal_insight_mod1 <-lmer(reduced_interpersonal_insight ~ environmentalist + (1| subreddit), data = comments_unified)violations_of_social_conventions_mod1 <-lmer(violations_of_social_conventions ~ environmentalist + (1| subreddit), data = comments_unified)insistence_on_sameness_mod1 <-lmer(insistence_on_sameness ~ environmentalist + (1| subreddit), data = comments_unified)ASD_mod1 <-lmer(ASD ~ environmentalist + (1| subreddit), data = comments_unified)anxiety_mod1 <-lmer(anxiety ~ environmentalist + (1| subreddit), data = comments_unified)OCD_mod1 <-lmer(OCD ~ environmentalist + (1| subreddit), data = comments_unified)summary(reduced_contact_mod1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: reduced_contact ~ environmentalist + (1 | subreddit)
Data: comments_unified
REML criterion at convergence: -7219.7
Scaled residuals:
Min 1Q Median 3Q Max
-4.8685 -0.6076 0.0581 0.6134 3.2930
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 8.451e-05 0.009193
Residual 1.555e-03 0.039438
Number of obs: 2000, groups: subreddit, 12
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) -0.120327 0.004043 4.743266 -29.759 1.41e-06 ***
environmentalist -0.010572 0.006616 5.976216 -1.598 0.161
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.611
summary(reduced_empathy_mod1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: reduced_empathy ~ environmentalist + (1 | subreddit)
Data: comments_unified
REML criterion at convergence: -6938.4
Scaled residuals:
Min 1Q Median 3Q Max
-3.4677 -0.6526 0.0454 0.6816 3.1539
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 7.651e-05 0.008747
Residual 1.792e-03 0.042331
Number of obs: 2000, groups: subreddit, 12
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) -0.048468 0.003912 6.700645 -12.388 7.27e-06 ***
environmentalist 0.004090 0.006471 8.248530 0.632 0.545
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.605
summary(reduced_interpersonal_insight_mod1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: reduced_interpersonal_insight ~ environmentalist + (1 | subreddit)
Data: comments_unified
REML criterion at convergence: -5874.6
Scaled residuals:
Min 1Q Median 3Q Max
-4.1675 -0.4680 0.1845 0.6741 2.1920
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 4.597e-05 0.00678
Residual 3.061e-03 0.05532
Number of obs: 2000, groups: subreddit, 12
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.054882 0.003402 5.053271 16.131 1.53e-05 ***
environmentalist -0.010345 0.005765 5.086061 -1.795 0.132
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.590
summary(violations_of_social_conventions_mod1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: violations_of_social_conventions ~ environmentalist + (1 | subreddit)
Data: comments_unified
REML criterion at convergence: -6394
Scaled residuals:
Min 1Q Median 3Q Max
-2.7245 -0.6985 -0.0963 0.5859 3.9997
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 0.0000877 0.009365
Residual 0.0023542 0.048520
Number of obs: 2000, groups: subreddit, 12
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) -0.194939 0.004234 4.749847 -46.04 1.76e-07 ***
environmentalist 0.003170 0.007042 5.748201 0.45 0.669
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.601
summary(insistence_on_sameness_mod1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: insistence_on_sameness ~ environmentalist + (1 | subreddit)
Data: comments_unified
REML criterion at convergence: -7029.3
Scaled residuals:
Min 1Q Median 3Q Max
-3.6779 -0.6375 -0.0105 0.5971 4.1889
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 9.095e-06 0.003016
Residual 1.721e-03 0.041481
Number of obs: 2000, groups: subreddit, 12
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) -0.068552 0.001869 6.053292 -36.681 2.43e-08 ***
environmentalist -0.006043 0.003097 4.421010 -1.951 0.116
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.603
summary(ASD_mod1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: ASD ~ environmentalist + (1 | subreddit)
Data: comments_unified
REML criterion at convergence: -3205.6
Scaled residuals:
Min 1Q Median 3Q Max
-4.8132 -0.4864 0.2302 0.7498 1.4612
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 0.0002009 0.01417
Residual 0.0116363 0.10787
Number of obs: 2000, groups: subreddit, 12
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.806791 0.006971 5.562273 115.741 1.27e-10 ***
environmentalist -0.006938 0.011804 5.797721 -0.588 0.579
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.591
summary(anxiety_mod1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: anxiety ~ environmentalist + (1 | subreddit)
Data: comments_unified
REML criterion at convergence: -5091.7
Scaled residuals:
Min 1Q Median 3Q Max
-6.3178 -0.3271 0.2744 0.6686 1.5142
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 3.984e-05 0.006312
Residual 4.534e-03 0.067336
Number of obs: 2000, groups: subreddit, 12
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.809612 0.003480 6.082865 232.631 3.02e-13 ***
environmentalist -0.005382 0.005863 5.255935 -0.918 0.399
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.594
summary(OCD_mod1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: OCD ~ environmentalist + (1 | subreddit)
Data: comments_unified
REML criterion at convergence: -3137.2
Scaled residuals:
Min 1Q Median 3Q Max
-4.7591 -0.4935 0.2171 0.7528 1.5172
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 0.0002382 0.01543
Residual 0.0120375 0.10972
Number of obs: 2000, groups: subreddit, 12
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.797555 0.007454 5.735849 106.990 1.09e-10 ***
environmentalist -0.007532 0.012606 6.174304 -0.598 0.571
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.591
Disappointingly, I find essentially no evidence that environmentalist and non-environmentalist communities are any different on any of these measures. There does not even seem to be a consistent trend in a particular direction.
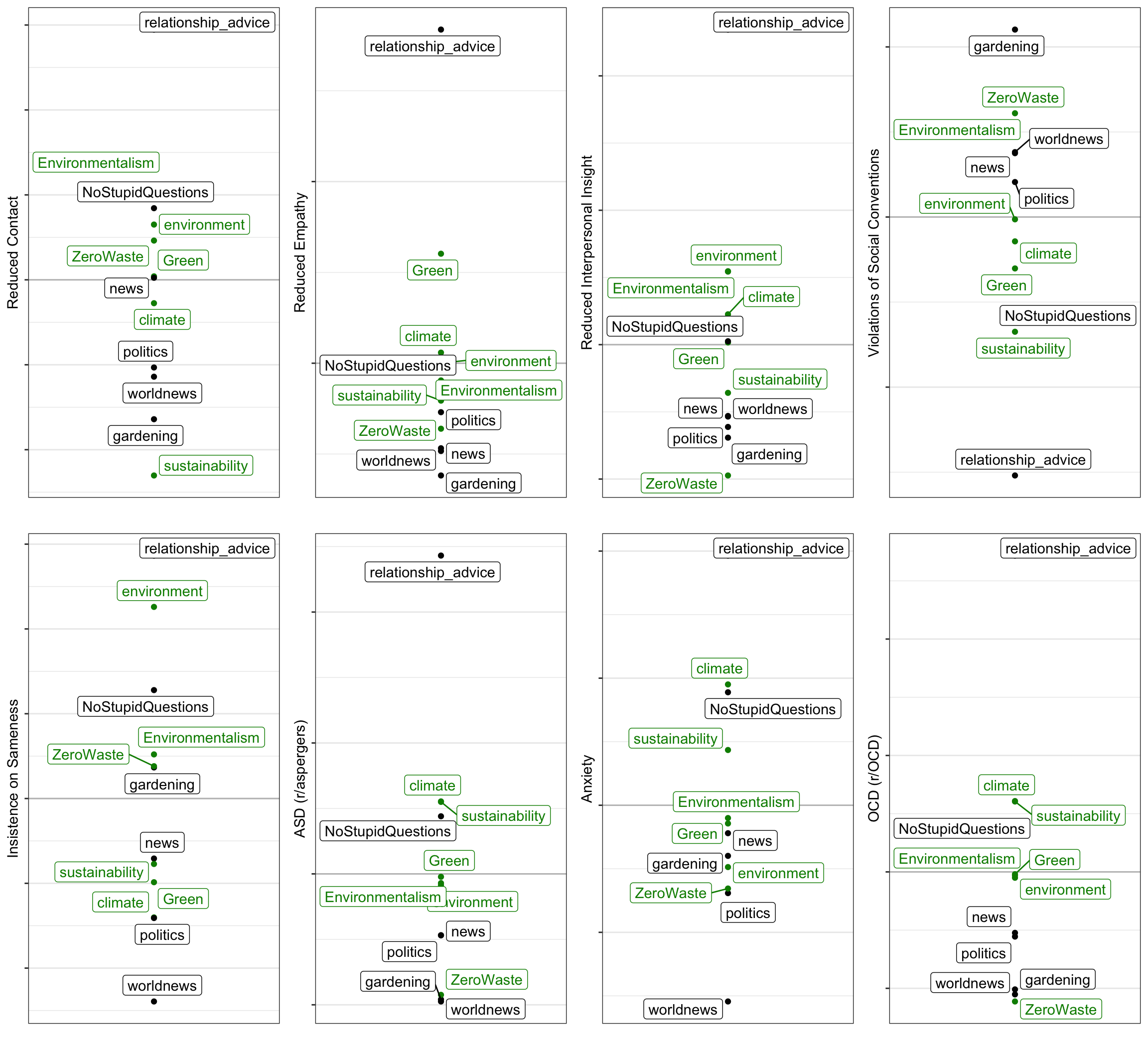
I do want to see this visually though. In particular, I’m interested in the model’s estimates for the random effect parameters. In other words: How does each subreddit score on each of the scales?
Here is that plot, with environmentalist subreddits in green. Higher indicates more of the given construct.
The only pattern that really stands out to me is how extreme r/relationship_advice is on every single one of the scales. Why that might be is beyond the scope of this post, but I suspect it will be obvious to anyone familiar with the tone of comments in that subreddit.
But What About in Their Non-Environmentalist Activity?
So maybe the actual content of environmentalist subreddits shows no difference, but I’m not as interested in the communities themselves as much as I am interested in the people in the communities. Maybe these people are displaying autistic or anxious features in their other activity? To test this, I will select 100 users from the environmentalist groups, and 100 users from the control, and retrieve up to 20 threads initiated by each. Then I will repeat the same analysis, this time adding user as a random variable in addition to subreddit.
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: reduced_contact ~ environmentalist + (1 | author) + (1 | subreddit)
Data: user_threads_unified
REML criterion at convergence: -6542.3
Scaled residuals:
Min 1Q Median 3Q Max
-4.0927 -0.5959 0.0701 0.5893 3.8971
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 0.0001566 0.01251
author (Intercept) 0.0001212 0.01101
Residual 0.0012784 0.03575
Number of obs: 1785, groups: subreddit, 902; author, 140
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) -0.119735 0.002188 131.203764 -54.732 <2e-16 ***
environmentalist -0.002693 0.002862 117.789048 -0.941 0.349
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.747
summary(reduced_empathy_mod2)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: reduced_empathy ~ environmentalist + (1 | author) + (1 | subreddit)
Data: user_threads_unified
REML criterion at convergence: -6300.2
Scaled residuals:
Min 1Q Median 3Q Max
-2.6696 -0.5859 0.0332 0.6245 3.5975
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 0.0002459 0.01568
author (Intercept) 0.0002170 0.01473
Residual 0.0013902 0.03729
Number of obs: 1785, groups: subreddit, 902; author, 140
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) -0.048570 0.002651 132.257159 -18.320 <2e-16 ***
environmentalist -0.003120 0.003482 118.658086 -0.896 0.372
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.744
optimizer (nloptwrap) convergence code: 0 (OK)
Model failed to converge with max|grad| = 0.00241565 (tol = 0.002, component 1)
summary(reduced_interpersonal_insight_mod2)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: reduced_interpersonal_insight ~ environmentalist + (1 | author) +
(1 | subreddit)
Data: user_threads_unified
REML criterion at convergence: -5630.3
Scaled residuals:
Min 1Q Median 3Q Max
-4.5910 -0.4614 0.1029 0.5887 2.6968
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 0.000468 0.02163
author (Intercept) 0.000268 0.01637
Residual 0.001966 0.04434
Number of obs: 1785, groups: subreddit, 902; author, 140
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.069887 0.003096 130.851486 22.57 <2e-16 ***
environmentalist -0.004004 0.004043 114.490448 -0.99 0.324
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.743
summary(violations_of_social_conventions_mod2)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: violations_of_social_conventions ~ environmentalist + (1 | author) +
(1 | subreddit)
Data: user_threads_unified
REML criterion at convergence: -6023.4
Scaled residuals:
Min 1Q Median 3Q Max
-2.9535 -0.6603 -0.0524 0.5843 3.6351
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 0.0003082 0.01756
author (Intercept) 0.0004030 0.02008
Residual 0.0015711 0.03964
Number of obs: 1785, groups: subreddit, 902; author, 140
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) -0.177732 0.003294 127.633852 -53.96 <2e-16 ***
environmentalist 0.003834 0.004356 116.003520 0.88 0.381
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.743
summary(insistence_on_sameness_mod2)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: insistence_on_sameness ~ environmentalist + (1 | author) + (1 |
subreddit)
Data: user_threads_unified
REML criterion at convergence: -6640
Scaled residuals:
Min 1Q Median 3Q Max
-4.3837 -0.6040 -0.0604 0.5654 4.7515
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 6.992e-05 0.008362
author (Intercept) 1.061e-04 0.010301
Residual 1.274e-03 0.035694
Number of obs: 1785, groups: subreddit, 902; author, 140
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) -0.063042 0.002045 129.323458 -30.823 <2e-16 ***
environmentalist -0.002365 0.002689 118.214386 -0.879 0.381
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.750
summary(ASD_mod2)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: ASD ~ environmentalist + (1 | author) + (1 | subreddit)
Data: user_threads_unified
REML criterion at convergence: -3265.7
Scaled residuals:
Min 1Q Median 3Q Max
-3.5880 -0.5497 0.0889 0.6412 2.4166
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 0.002953 0.05434
author (Intercept) 0.002085 0.04566
Residual 0.006437 0.08023
Number of obs: 1785, groups: subreddit, 902; author, 140
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.799575 0.007542 134.279751 106.017 <2e-16 ***
environmentalist -0.006601 0.009923 118.225715 -0.665 0.507
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.739
summary(anxiety_mod2)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: anxiety ~ environmentalist + (1 | author) + (1 | subreddit)
Data: user_threads_unified
REML criterion at convergence: -4775.9
Scaled residuals:
Min 1Q Median 3Q Max
-5.3178 -0.4576 0.1622 0.6339 2.1049
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 0.0007975 0.02824
author (Intercept) 0.0005817 0.02412
Residual 0.0031042 0.05572
Number of obs: 1785, groups: subreddit, 902; author, 140
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.798074 0.004266 138.183399 187.073 <2e-16 ***
environmentalist -0.002018 0.005598 121.964326 -0.361 0.719
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.742
summary(OCD_mod2)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: OCD ~ environmentalist + (1 | author) + (1 | subreddit)
Data: user_threads_unified
REML criterion at convergence: -3179.5
Scaled residuals:
Min 1Q Median 3Q Max
-3.5033 -0.5603 0.0851 0.6445 2.4080
Random effects:
Groups Name Variance Std.Dev.
subreddit (Intercept) 0.003211 0.05666
author (Intercept) 0.002235 0.04728
Residual 0.006687 0.08177
Number of obs: 1785, groups: subreddit, 902; author, 140
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.79217 0.00779 134.04136 101.696 <2e-16 ***
environmentalist -0.00686 0.01025 117.91558 -0.669 0.505
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
envrnmntlst -0.738
Still nothing approaching statistical significance. Everything except violations of social conventions actually shows a tiny negative trend (that is, environmentalists are slightly less autistic/anxious).
Actually, these findings are consistent with this paper4, which likewise found that autistic traits are slightly negatively correlated with pro-environmental attitudes and behaviors.
Of course, this is not to discount Greta Thunberg’s account of her own psychological superpowers. She may well be an exception to the rule.
The somewhat underwhelming conclusion of this research is therefore:
Most Reddit environmentalists are not Greta Thunberg.
Atari, M., Omrani, A., & Dehghani, M. (2023, February 24). Contextualized construct representation: Leveraging psychometric scales to advance theory-driven text analysis. https://doi.org/10.31234/osf.io/m93pd↩︎
Horwitz, E., Schoevers, R.A., Ketelaars, C., Kan, C.C., Lammeren, A.V., Meesters, Y., Spek, A.A., Wouters, S., Teunisse, J.P., Cuppen, L., Bartels, A.A., Schuringa, E., Moorlag, H., Raven, D., Wiersma, D., Minderaa, R.B., & Hartman, C.A. (2016). Clinical assessment of ASD in adults using self- and other-report : Psychometric properties and validity of the Adult Social Behavior Questionnaire (ASBQ). Research in Autism Spectrum Disorders, 24, 17-28.↩︎
Taylor, E. C., Livingston, L. A., Callan, M. J., Hanel, P. H. P., & Shah, P. (2021). Do autistic traits predict pro-environmental attitudes and behaviors, and climate change belief? Journal of Environmental Psychology, 76, Article 101648. https://doi.org/10.1016/j.jenvp.2021.101648↩︎